在上篇 DAY2 知識之章-理解資料本源 中,我們介紹到本次的資料集內容,了解需要分析的資料集後,我需要選擇一個適合的數據架構,於是今天我們要來了解一下 Data Lake、Data Warehouse and Data Lakehouse 之間的差異。
在本篇開始之前,要先感謝 Vu Trinh 在數據工程領域上持續推出的文章,將深度的內容使用簡易圖解式說明,真的對我有很大的幫助,本文我也將引用一些他繪製的圖片來做說明。
同時也想感謝在某時某刻訂閱一些知識文章、購買相關課程、書籍的那個自己,投資自己成長也是一筆非常划算的交易。
不懂就學,就算我愚笨,總有一天也會學會,我是這樣不斷的告誡自己。
回想當年,我剛社會工作時,其中有一項工作是協助各單位的使用者了解公司資料,並幫助他們使用 Power BI 建立自己想要的可視化報表。
那時一切都很簡單,公司只有一個 OLTP 的資料庫,我可以直接從資料庫內清楚地找到各維度的資料,透過簡單的資料萃取後,再使用 BI 將資料從 DB 同步到 Power BI 內,接著組成星型資料模型,就可以直接應用於 BI 報表開發上,提供使用者簡單乾淨的可視化報表,幫助他們做決策。
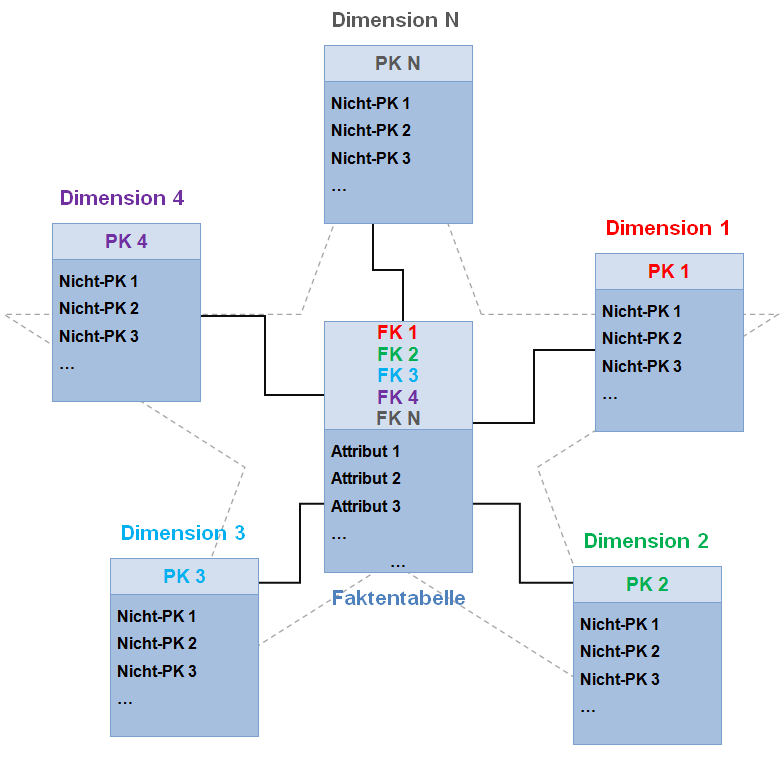
圖片來源-維基百科
隨著職涯發展,當我開始換到規模較大的公司時,我發現公司每個系統都有獨立的資料庫,而且各個資料庫都有自己獨特的資料定義方式。
這時使用者的需求來了,他們想要了解來自於 A、B、C、D 等不同系統所彙整的資料,希望我們幫忙將所有的資料整合成一份資料集,近一步幫助他們分析。
於是我發現困難度直線的上升,已經不是當初這麼輕易將某個 OLTP 資料庫的資料做萃取後,接著直接建立資料模型,這種簡單的方式能夠解決。
而是根據每次不一樣的需求,我需要先撈出各系統的資料,並將資料做處理後,整合成一份新的資料集,再提供給使用者應用,這樣的做法耗時且沒有統整性,容易出錯。
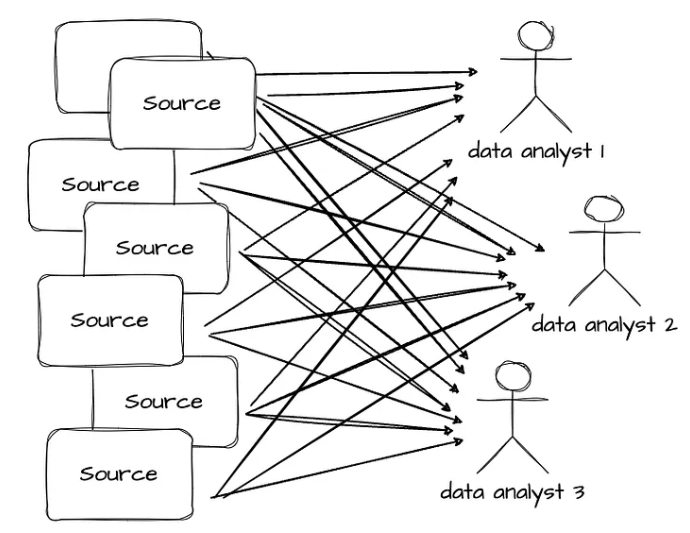
圖片來源-Vu Trinh
此時,資深的前輩說了一句話,你可以從「資料倉儲」中取得相關資料!
當時我一臉呆滯,表情困惑,心裡在想著到底什麼是資料倉儲?
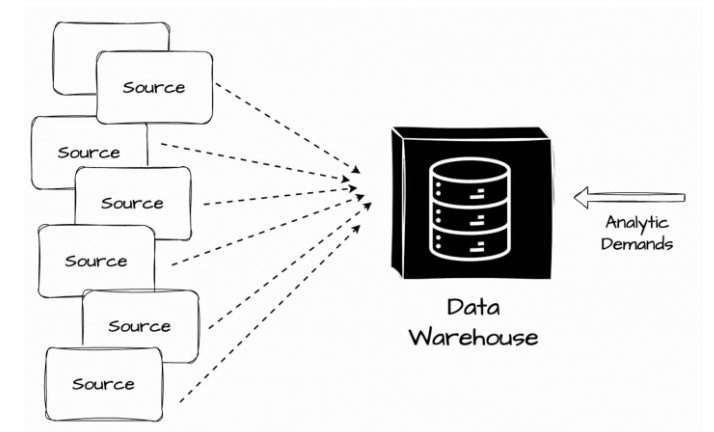
圖片來源-Vu Trinh
資料倉儲是一個儲存庫,可以在其中集中、儲存和管理來自多個資料來源的大量數據,以滿足公司的 OLAP 工作負載。
資料從多個來源提取後,轉換成預先定義的結構化資料型態,並載入到資料倉儲中。資料倉儲透過提供集中式資料儲存和檢索儲存庫,幫助我們管理企業和組織的資料,從而實現更有效率的資料管理和分析,我們可以直接在裡面做 Query 分析,也可以組成 View 表後,再將資料源提供給 BI 工具進行報表設計與分析,從而滿足使用者多系統資料整合的需求。
但隨著系統的優化,越來越多的資料,不僅是以結構化的資料方式做儲存,也可以是圖片、音檔、文字文件等非結構化資料,這給關聯式資料倉儲帶來了新的挑戰。此時早已存在的資料湖概念,才開始慢慢被人們提倡。
資料湖是一個概念,它描述了將大量資料以其特定格式(在 HDFS 中,或之後在雲端物件儲存中)儲存的過程。與傳統資料倉儲不同,資料湖不需要我們事先定義模式,因此所有資料(包括非結構化資料)都可以儲存在資料湖中,而無需擔心格式約束。
一開始,資料湖便宜的「儲存成本」與「不限制資料結構」的優點,讓工程師打算用來取代開發資料倉儲,但這種方法存在許多嚴重的缺陷,由於缺乏資料倉儲應有的資料管理功能,例如:資料索引、資料品質、資料完整性、ACID 約束以及資料 DML 支援等,資料湖很快就變成了「資料沼澤」。
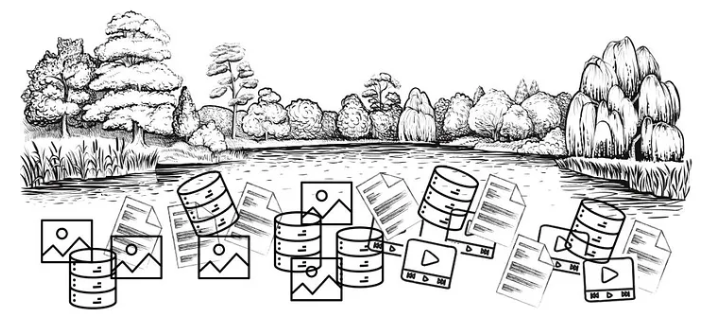
圖片來源-Vu Trinh
於是資料湖和資料倉儲結合的想法開始出現。
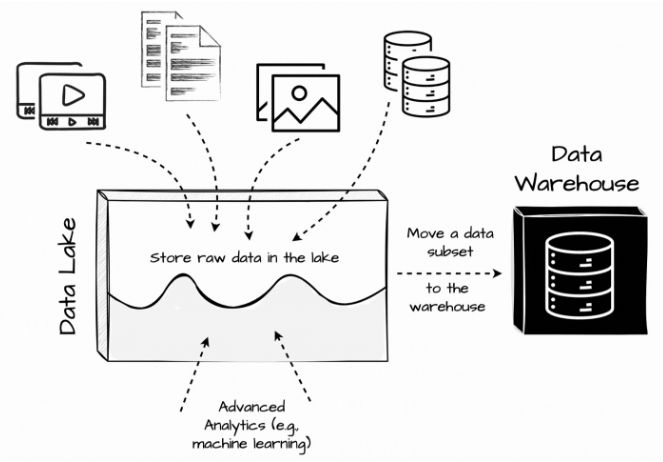
圖片來源-Vu Trinh
將結構化與非結構化資料,轉換到儲存成本相較於便宜的資料湖內,主要用途:
但維運上就會需要特別注意一些事項:
以上這些問題,也顯示出維持兩套儲存系統的困難。
因此,近年出現了新的架構設計,也就是 Data Lakehouse 的架構出現了。
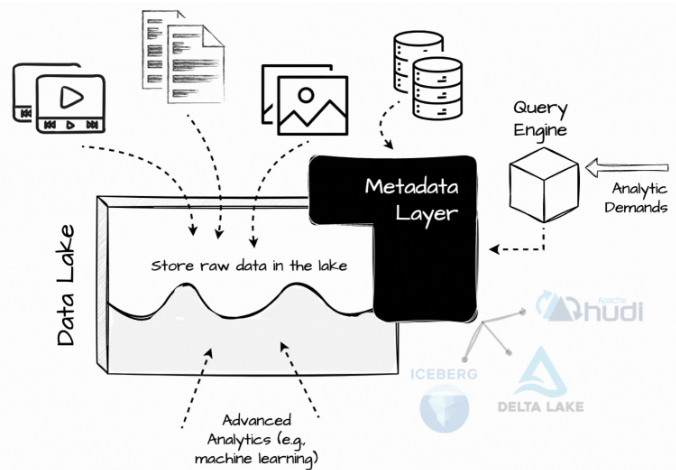
圖片來源-Vu Trinh
Data Lakehouse 是一種基於低成本儲存的架構,增強了傳統的分析行 DBMS 管理和效能特性,例如 ACID、版控、快取、查詢最佳化等優勢。
與過去直接將資料處理引入資料湖的做法不同,Lake house 多了一個元資料層 (Metadata layer),常見的有:
他們將資料「更新插入」和「增量處理」的功能引入了 Data Lake。
在 Lakehouse 中,所有與資料相關的操作必須經過這些開放的表格式,才能啟用資料倉儲功能,例如:
這些表格式還會幫忙記錄統計訊息,幫助查詢引擎修剪不必要的資料,例如:min/max value。
依照多數的文章顯示,未來 Lakehouse 架構將持續快速的發展。
每種架構都有適合使用的場景,我們需要配合公司、客戶、自己各個使用者的需求,來加以調整基礎設施的建置,同時也要思考可擴長性、效能、維運人員成本、服務成本等。
隨著時間流動,新技術也不斷的推陳出新,讓我們一起跟著時代進步吧!
本篇我們簡單的介紹了 Data Lake,Warehouse and Lakehouse 的演化和優缺點,下篇我們將一起來了解 「DAY4 知識之章- Open Data Format」。
[1] 維基百科 - 資料倉儲
[2] 維基百科 - 星型模式
[3] Vu Trinh - The Data Lake, Warehouse and Lakehouse
[4] Power BI
[5] OLAP 和 OLTP 有什麼區別?
[6] 什麼是資料湖?
[7] Data Lakehouse

